
Can 20 Million+ documents change the First World War?
Abstract
We present here an interdisciplinary digital humanities project on the Great War of particular interest to computer scientists, English literature specialists, and historians. The project statement outlines the motivations for the project, the methods used, the data produced, and our preliminary interdisciplinary analyses of the results.
Introduction
When data-mined, will 20 million documents reshape our understanding of the First World War? We present here a interdisciplinary research project that investigates records pertaining to the Great War using a Linked Open Data approach. Ultimately, we hope to take archives of digitized documents, extract the written data using image processing algorithms, and turn the resulting information into a structured Linked Open Data dataset. We expect that the large knowledge base generated from our efforts would support further research in different humanities and computer science areas, and that over time, it could be linked to other databases. Thus the database we generate could function long term as a standalone research resource for other researchers, while at the same time, through its links with general databases such as dbpedia, it could provide additional contexts to research projects in other time periods or disciplines.
Background
Previous approaches to analyzing historical documents have been hampered by technology and data that was not available in a format that provided for ease of manipulation and experimentation. For researchers who wish to data-mine thousands or millions of documents, the best means of digitizing those documents is Optical Character Recognition (OCR), a process that allows for large-scale data-driven approaches such as data-mining and distant reading. The advantage of data-mining with OCR data is twofold: it enables the reading of documents more rapidly than could be accomplished by single researchers’ eye-reading practices, and it enables the reading of patterns in the documents themselves. Although digitization renders documents accessible to scholars who may not be in a position physically to search them at an individual archive, the time improvement involved in that kind of digitization is insufficient for our purposes. Like all data-miners, we wish to analyze large numbers of documents simultaneously.
At present, not many datasets are formatted for the kind of search that we have undertaken: a computer image of a text (i.e. scanned images or Portable Document Format [PDF] files) are not searchable for keywords or accessible to statistical analysis because they are not machine readable. PDF snapshots allow scholars who wish to inspect single specific documents to access them through an online web portal, and they are a far more common means of digitizing paper documents. These snapshots can be ideal for scholars who pursue the close reading methods familiar from the pre-digital days when paper records were the primary materials that supported research, but scholars cannot analyze them in the aggregate. For large-scale approaches to digitized data, researchers require more than images that convey only simple metadata, as PDFs do. Instead, they require the actual contents of the documents be made available.
Optical Character Recognition costs less than scanning, although many organizations and institutions have opted for the latter. Notable exceptions are archive.org and the HathiTrust, both of which make the contents of the imaged documents available to end users in different formats, including Optical Character Recognition. End users of OCR’ed documents are often more specialized users (academic researchers being a prime example). A smallish subset of the general public, they must constantly make the case for the OCR process over simple image scanning.
We have found that in the case of archival documents, low levels of funding have resulted in a preference for PDFs, which can quickly be made available for viewing on the internet. There is a price to pay for preferring the PDF, and researchers pay it in terms of their diminished understanding of how data-mining could reshape or enhance traditional critical methods in the humanities, particularly those applied to the interpretation of historical documents.
The project is currently hosted both at the University of Waterloo and on a commercial private server for the foreseeable future. The project participants secured small grants to facilitate the transcription of the documents they data-mined. Although there is a great deal of discussion around the benefits of transdisciplinary projects, and different stakeholders have expressed a good deal of interest in the specific wartime records that the project leaders have OCR’ed for the project, funding for transdisciplinary projects remains difficult to secure. Before the kind of work described below can be undertaken on a truly large scale, more records must be OCR’ed rather than PDF’ed.
Previous work
Similar Linked Open Data projects include the large Europeana project, the Seco WW1 Project [Mäkelä et al. 2014] which focuses on Belgian and German data, and the completed Out of the Trenches project [PCDHN 2012]. The British Library, the German National Library and the French National Library have similarly created pilot projects to make their data available using a Linked Open Data approach.
Data set creation
The Great War was the first truly mechanized conflict, and it generated an unprecedented amount of paper records. Many of these records may be found on portal websites recorded as scanned (PDF) images. Although it was not always possible to data-mine the digitized records we found in this form, we did “crawl” their portal webpages and, using advanced image processing algorithms, we created a dataset of facts about and events during the war. Figure 1 is a spatial representation that visualizes the breath of the data collected in this manner and also offers a truer (though still rough) picture of the area over which the War--as embodied in the people who travelled for war-related purposes--stretched.
 Figure 1. A map representing the location information attached to all of the facts contained with the Great War database.
Figure 1. A map representing the location information attached to all of the facts contained with the Great War database.
Warren began to create this database by collating sites where he found records of people and events related to the war. This enabled us to visualize the extent of the spatial coverage of the data accumulated so far. The specific data sources used include the War Diaries as made available by Library and Archives Canada, the Commonwealth War Graves data, the Old Weather ship data from the war, trench geometries extracted from scanned maps obtained from the Imperial War Museum map collection and OCR’d regimental histories. The database is populated with the people involved in the Canadian Expeditionary Force and the Royal Newfoundland Regiment, and it includes, too, the events that affected them and the places that they visited.
The dataset is constructed using a Linked Open Data [LOD] approach using the Semantic Web, the only approach currently able to handle the complexity of the data. Consensus within the Linked Open Data community is that the reuse of ontologies should be pursued whenever possible. Warren followed this guideline when recording standardized elements, such as modern GPS coordinates and dataset descriptions, but he had to create specialised ontologies to deal with domain specific data such as military ranks, war graves and specialised military coordinate systems. The complete documentation for the created ontologies is located at http://rdf.muninn-project.org/ and has also been partially published [Warren 2014, Dean-Hall 2013] as seperate academic works. The database itself contains about 90 millions triples and references about 300 thousand people. It is available through a SPARQL access point and as well as database dumps.
The information in the database is made available under a Creative Commons Attribution license that is intended to permit as much use of the data as possible while promoting the use of good scholarly practice. Most of the documents within the database were created before the 1932 copyright convention, greatly simplifying licensing decisions. One exception has been with the Canadian Expeditionary Force medical case sheets data set. Due to the funding mechanisms used to perform the extraction of the data from the archival documents, the dataset is under Crown Copyright while simultaneously also being under the Creative Commons Attribution license. This has not been an obstacle to the distribution of the data, but we mention it as an example of the inherent complexity of data-set licensing even in the case of old data.
Data-mining the War Diary Dispatches of the Princess Pat’s Light Infantry
We describe here a preliminary result of our data-mining attempt that focused on the dispatches contained in the War Diaries of the Princess Patricia's Light Infantry War Diaries. We presented a preliminary version of this research as an invited lecture at the Stratford Institute in March 2011.
We experimented with data-mining a limited dataset of dispatches written to and from the trenches by officers of the Princess Patricia’s Light Infantry (PPCLI) during 1916 in the Somme. We wanted to know more about the potential of such documents to change our understanding of how the people who fought the war made sense of the experience. We begin by reviewing the dominant understanding of how the people who lived in that period came to view the world they inhabited as a result of living through the conflict. According to this view, a key resource for comprehending how contemporary views of the world changed after the war is wartime literature, and a key vector for measuring that change is the use of irony in that literature.
In his seminal monograph The Great War and Modern Memory, Paul Fussell contends that some literature of the First World War, particularly the poetry of war poets such as Wilfred Owen, Siegfried Sassoon, and John McCrae define the memory of the war both for those who lived through it and for those in posterity who read about it [Fussell 2000]. Literary representations of the conflict offer the most appropriate and the best opportunities for thinking about the war and its meaning because they convey larger, less tangible but very real truths about the event and its consequences that nonliterary representation does not. This idea of literature is not unique to the poetry, novels, and memoirs of the Great War: The capacity to name the zeitgeist of a time is seen as the potential property of all literature, as Fussell reminds readers in his opening chapter. Literature evolves from the human desire to give readers the complexities of human experience and to tell truths about that experience that are only partly and imperfectly conveyed in the era’s non-literary writing. Fussell contends that the literature that comes out of the war ushered in a new age of “terrible,” “mortal irony” (3-4), an irony first and most powerfully conveyed in the poetry and fiction of the conflict years, and subsequently absorbed by the population as the appropriate attitude to take towards the postwar world. This mordant irony affirms the irreparable physical, moral, and mental disintegration of the world the writer inhabits.
Nonliterary writing from the trenches does not convey this same sense of irony, however. This in itself may not be surprising, as these writers are less concerned with art and more with rapid, clear, and efficient communications. What surprised us, however, was the distinctness of the irony in these workaday documents. Not only do they differ in tone and content from the work of the modern war poets, but they invite further examination on their own terms, and not only in relation better-known ironic literary texts.
This insight invites humanities researchers to rethink their assumptions about how to approach irony itself--not necessarily, or only, through the “great texts” as exemplary texts that epitomize the irony of the age, but instead through the many more numerous if less eloquent rank-and-file documents the irony of which may demand a different reading that does not take their inferiority for granted. Maybe a serious consideration of this prospect will result only in a reaffirmation of the original view that literature does in fact express the zeitgeist that all writers and citizens at a historical moment of crisis experienced. Or maybe some scholars will find it necessary to reconsider their entire approach to literature. The point is that data-mining puts the challenge to literature scholars.
The idea of literature with which Fussell works is that of literature as the harbinger of paradigm shifts in ideas and attitudes that are also expressed later, and less poetically, in various kinds of nonfiction. Literature represents what does not yet have a name. According to this idea, what one finds in great literature, one will find to some extent in all the writing of the time and place, which will register (if less eloquently) the same shifts--in the case of writers during the First World War, the primary shift is toward an insurmountable irony and cynicism. Now that there are datasets to mine, we can interrogate the truth of this view. Do rank-and-file soldiers express the same shift towards “mordant” irony in their writing?
We data-mined the War Diary for the Princess Patricia’s Light Infantry (PPCLI) in October 1916 at Courcelette, France. This collection contained the operations orders written prior to the engagements in which the company took part, the events recorded within the diary itself, and the dispatches received and sent by PPCLI headquarters during this period. The original documents were first microfilmed, scanned by Library and Archives Canada. The images were transcribed by Michael Thierens and edited by Donna Walker, Ross Toms and Stephen K. Newman. The text was then converted into NIF Linked Open Data by Warren, linked to CEF personnel records and geolocated using a conversion program described in [Warren 2014].
At first glance, these documents appear to share many of the qualities and insights of the great wartime poetry Fussell discusses. Like that poetry, it describes privation, confusion, instability, and broken communication. Although Fussell looks the war through only a few carefully-chosen literary texts, and we looked at it through many less distinguished non-literary ones, we noted confusion and frustration just as Fussell does in the poetry. But some simple data-mining techniques find other meanings in the diaries as soon as we look for patterns or repetitions in the dataset. While Fussell concentrates on exceptional texts such as the handful of sonnets that Sassoon and Owen wrote about trench battle, data-mining looks for repetitions across great numbers of texts, for the regular and recurring rather than the extraordinary or unique. Knowing that most of the messages contained in it were written under intense time pressure, we decided that a useful initial search would parse the length of (1) messages and (2) sentences in search of regular patterns across those lengths. Our hypothesis was that in the context of battle, long messages might be extremely rare, but being rare they might signal unique events. Where time is precious and lives may depend on speedy action and communication, where do longer messages appear and why? This search of longer-than-average messages and sentences yielded a group of longer messages from the dataset as a whole that were around three times the length of the other messages in the set. After isolating them we looked at each one in relation to the other messages sent to and from the companies in the same battalion on that same day. We wanted to get a sense of their length relative to the other messages in their immediate vicinity and also how many messages were sent on the day when the longer message appeared. Our intuition was that the number of long messages would decline at times of intense fighting and that what long messages there were would not be written on the frontline but behind it somewhere, at a battalion command post. At this early stage, the initial data-mining search, our search strategies avoid analyzing content and focus on text elements like length. We are reading not specific words in the sentence but the number of words in the sentence, not the specific statements, commands etc. in the message but the number of sentences in the message, and from their how these numbers compare to the numbers in the other messages near these longer ones.
The messages were processed for statistical analysis using the commonly available style (1) unix utility. The study of the PPCLI dispatches required some pre-processing in that these messages are primarily send through heliographs, signal flags and telegraphs that often require a very terse writing style. In combining the particularities of the transmission methods and the linguistics, we made the decision to terminate a sentence when a telegraphic stop (‘AAAA’) was used.
The average number of messages sent on any given day recorded in the file can rise to a dozen dispatches when an offensive is underway, though routine administrative messages were not retained. The average length of a message is about 59 words, through whenever a significantly longer message forms part of the day’s correspondence, it length can be up to 300 words.
Once the longer messages were isolated and we looked more closely at where they showed up, we discerned some repetitive characteristics:
1. very long messages are present on days with above-average numbers of messages in general (a finding that went against our intuition);
2. long sentences tend to be found in longer-than-usual messages;
3. long messages are preceded and followed not by other long messages but by very short ones.
After analyzing sentence length, we embarked on a limited content analysis, and we found that we needed to look at the content not only of the messages we had started off by identifying but the sequences in which these messages appeared; it is difficult to isolate one message from another to which it may be replying or connected in some other way. The sequences we looked at were 1-2 short messages—the long message—1-2 short messages, and we found that this was sufficient to scrutinize the components of the longer message. We found that the messages that immediately preceded the long message typically had elements (bits of information, actual phrases) that are repeated in the subsequent long message, while the message or two that follows it often supply a short status report from some part of the battlefield. From here, we undertook our closer content analysis.
Our first example comes from the messages sent during the day of October 10th, 1916, much of which is spent trying to secure a portion of Regina Trench. The Regina Trench in 1916 is really part of the Battle of the Somme as it continued through the rest of that year after June 6. The fighting at the front by the Canadian corps on this October day belongs to a two-month-long effort, beginning on September 15th, to take a section of the trench. The specific part where the Princess Pats are is near Miraumont Road. On this day there are two long messages nested in a total of 19 notes sent that have survived as part of the file. The first of these is preceded by two very short communiqués, one of which reports that the 43rd Battalion “have pushed forward beyond Regina Trench to high ground” and the next of which states that according to the latest report, “the 43rd Battalion does not hold Regina Trench.” The reports appear to have been sent within an hour of one another, one from the Princess Patricia’s Canadian Light Infantry or the PPCLI, which acronym refers to infantry headquarters (at 8:50 am), and the other from the 3rd Canadian Division (at 9:50 am). The longer message that follows these two brief notes begins: “There appears to be some doubt as to whether the 9th B[riga]de has reached objective. The Brigadier wishes our portion of Regina Trench assured. The following operations will be carried out at once.” The message then gives a series of instructions for the coordinated advance of the 1st, 2nd, 3rd, and 4th companies that specify not only where each will go but what other actions will have to be taken at each stage of the movement forward. The 1st and 3rd companies are told to move to Sudbury Trench right away and once there, ascertain “if there is room” in the ‘jumping-off trench’ for the 3rd company to move on to it. The next action depends on the answer to that question, as does the action to be taken after that, and so on.
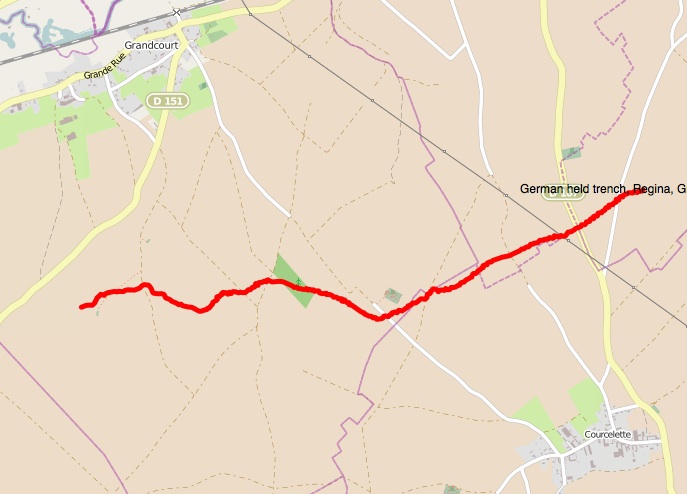
Figure 2. The location of the Regina trench (British Name) on a modern day map of France at about 2.7238W, 50.0708N. Both feature nomenclature and the geometry of the trench are available as Linked Open Data within the database.
This message carefully choreographs the next steps the companies must take in the field. The coordinated movements outlined have the troops literally dancing through a minefield, as the message also acknowledges: Of the twelve sentences that make it up, four begin with the subordinating conjunction “If,” and four include dependent clauses that start with either “if” or “whether.” If and whether are the doubt words of the English language, conditionals that identify whatever comes after them in the sentence as unknown, a possibility but not a certainty. They warn listeners to be prepared for the opposite of the statement to be true. Such conjunctions and their clauses are almost completely absent from short messages in the dataset, but in this longer missive, they constitute half the communiqué.
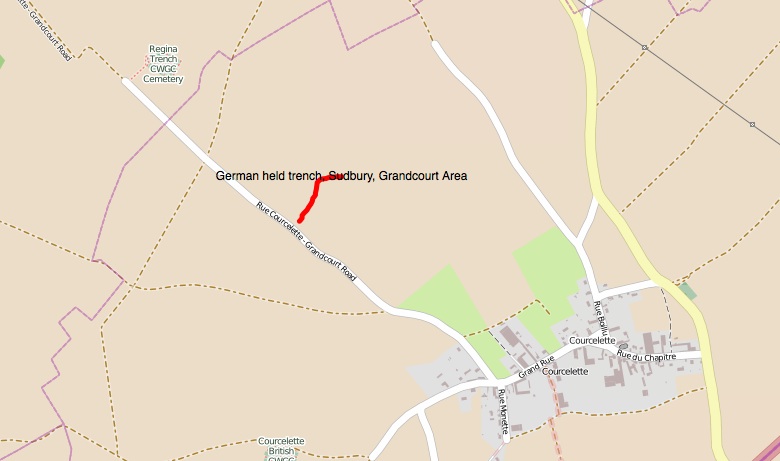
Figure 3. The location of the Sudbury Trench near Regina trench on a modern day map of France at about 50.0629N, 2.7356W. Both feature nomenclature and thegeometry of the trench are available as Linked Open Data within the database.
This particular long message suggests, then, that it differs substantially from the bulk of shorter notes in the dataset not only in terms of its length but also its content. Significantly, many of the conditional statements in the message refer to situations either reported in earlier notes as realities on the ground or included in orders. The command, for example, to “establish block with 43rd B[attalio]n” at West Miraumont Road and Regina Trench that appears in one of the short messages preceding this one returns here as a question. A “reconnoitering patrol” is ordered to see “whether” (emphasis added) that block was in fact made. The repetition of earlier orders like this one in conditional clauses reinforces the opening statement’s suggestion that this message is sent because “There appears to be some doubt as to whether the 9th B[riga]de has reached objective” (emphasis added). As the numerous conditionals indicate, the message stipulates to the uncertainty of the situation. It neither resolves that doubt nor ignores it. Rather, it admits that its authors know no more about the situation on the ground than do the officers-in-charge to whom it is sent. At the same time, the long message brings what clarity it can to the situation by identifying precisely what is not known and outlining a clear series of actions the authors believe will produce this missing information.
That the message informs all four battalion companies at once of this coordinated effort and then asks them to submit full reports once they have carried out their orders emphasizes planning and command as means of controlling the unknown while acknowledging its pervasive presence.
Two and a quarter hours after this message is sent, another lengthy memorandum is written, this time by an officer-in-charge on the front line, where presumably there is even less time to compose long missives than there is at infantry headquarters. As with the earlier message, a very short note precedes the longer one and informs some of its contents. Both the short and the long, in this case, are composed by the same writer, Major H.E. Sullivan of No. 2 Company. The brief note tells the PPCLI that he is withdrawing No. 2 Company, and possibly also No. 4 Company, from Regina Trench, effectively doing the opposite of the order he was given in the earlier message. Directed by that message to reconnoiter Regina Trench from the “jumping off” trench, he has in fact moved his company backwards in to Fabeck Trench, and no matter what information reconnoitering might obtain, he has also determined that poor weather pre-empts any further forward movement.
The long message that follows repeats all this information but elaborates why he has decided to take these actions. For instance, Sullivan clarifies the status of the Regina Trench segment that was one of the major unknowns with which the infantry command had been dealing. The fact is that troops he finds in the area are not engaged in a battle for this part of the trench. Rather, the enemy has taken it, and all troops have been forced to retreat. Sullivan also repeats the news he first reported in his earlier short message that “the whole of the RCR” have relocated to the “’jumping off’ trench” where his company had been ordered to go if advancement to Regina Trench proved impossible. That the trench has therefore become “crowded and dangerous” presents him with another immediate reason to move his men further back.
But dire as the conditions are, he does not make the decision to retreat on the evidence of his own eyes alone. “Before I withdrew my Co[mpany],” he writes, “I talked the matter over with Major Hudson of the RCR and he and his junior officers agreed with me that the trench was too crowded and that I should withdraw.” According to Sullivan’s account, then, he paused in dangerously crowded conditions with “fairly heavy” casualties for a trench consultation that endorsed his reading of the frontline circumstances and the action he would take in response to it.
A couple of obvious reasons for composing this long message near the battlefield present themselves: First, where commands have not been carried out, a fuller-than-usual explanation is in order, and second, where those who gave the commands lack crucial information about the front that the commanding officers have gained by going to the scene, the officers in charge need to convey that information to them thoroughly and accurately. But when these messages are flagged using a data-mining method that draws attention to the rarity of the long message in a sea of very short ones, other insights also present themselves.
These insights do not arrive without posing some risks. Once messages are flagged as having something in common with a very small group of other messages, it may be tempting to exaggerate similarities in the content. That said, our method also points out less obvious similarities that emerge in this kind of search that might go unremarked in searches that emphasize content first. In some ways, these two messages are very different. One is dominated by commands made from a distance. The other narrates a series of actions taken in rapid response to immediate circumstances. One is full of conditionals and speaks of future actions and contingencies; the other is written primarily in the past tense about what has already been done as opposed to what will be done “if…” One comes from behind the frontline while the other is sent from it. There may seem little reason to compare the two given these dis-similarities.
If we ask the questions “Does the length indicate any other sort of similarity?,” however, or again, “Why did these soldiers write long messages under severe time pressure rather than short ones?” we might notice that the messages, despite their differences, have a common effect: both offer stability to a situation that otherwise has little to none. That stability comes from their common focus on updating information about the front and on commands sent and received. The purpose of the first long message, to go by its opening sentence, is to clear up “doubt as to whether the 9th B[riga]de has reached objective”; the purpose of the second is to give command HQ the fullest possible picture of what exactly is going on in the trenches from someone who can deliver an eyewitness account. Although the first is full of “ifs” and “whethers,” it at least gives readers a clearer sense of what is known and what is not known about the front. Although the second presents a summary of commands not followed, it does so as part of an explanation that illuminates the real battle scene. Both messages foreground commands and how seriously commands are taken. We would argue that the second message is longer in part because the military, particularly a military involved in an unfolding, live contest, does not tolerate the flouting of a command hierarchy, and indeed, most of this message explains why Sullivan did not follow the original orders he received.
That Sullivan begins his message by describing the countermands with which he replaces his original orders stresses the fact that he did not follow them. Yet it also replaces those orders immediately with a series of new ones that he contends respond to the real situation on the ground, a situation about which (as the PPCLI memo implicitly recognizes) Headquarters commanders know almost nothing. The real emphasis thus falls not on the possibility of disobedience but on the constant, unbroken presence of direction for the troops. The attention here is drawn to the consistency of leadership in the face of chaos more than to the changing of the orders, a change for which explanation is needed but which the officer in charge can defend on the grounds of the new information he possesses and that his superiors away from the front do not. He therefore writes a lengthy message at this moment because confusion is particularly acute and increasing thanks to the frontline’s disconnection from Headquarters Command.
There is irony in Sullivan’s message, the irony that accompanies the recognition that what seems to be true and what is in fact true on the ground are two different things. This irony also sounds in Sullivan’s choosing to begin his memo by contradicting his commanding officers. The context for that irony is a context that, when approached through data-mining techniques that foreground the length of sentences in the surrounding communications and the extraordinary length of this particular message, indicates that irony emerges exactly where battlefield communications become most stressful. When things fall apart on the frontline, in other words, writers such as Sullivan become highly organized communicators who put their world back together using written text.
Some Humanities Conclusions: Open Data, Open Mind
A key feature of the close reading method, the researcher’s initial judgment about what kind of search of the text to undertake, remains the same in a data-mining search as it does in an individual researcher’s search. This initial decision still determines the data the search returns in the same way. The risk of bias is as real in data-mining as it is in any type of archival inquiry. Conversely, both types of search can also lead to unexpected discoveries that, if the researchers choose to pay attention to them, could be game-changers. Thus one possibility to which we keep an open mind in this study is that data-mining World War I records will not alter our understanding of the war, nor generate insights that significantly differ from those gleaned by lone scholars combing through paper archives on their own. It may perform some of his or her tasks more quickly, but the results it produces may not depart much from what we already have.
At the same time, we strongly suspect that with more records digitized to make searches like these possible, scholars will find insights about modes such as irony that have been unavailable to them using conventional eye-reading approaches to text. Once the text written by thousands of soldiers and other wartime participants becomes available, will we--can we--understand the era’s irony in the same way? Will we take as many cues from the wartime poets? It’s important for humanities scholars, both as researchers and educators, constantly to strive to see the past with new eyes so as to avoid allowing our interpretations of these events to atrophy, as has happened in the case of a war now normally viewed as a turning point to a new age of irony. The only way to find out is to develop much larger datasets of OCR’ed text than the ones to which scholars currently have access. Unless that happens, the digitization of data as PDFs or scans will only generate versions of the critical methods with which scholars worked before the advent of digitization.
Some Computer Science Conclusions: Visualizing the War
The extraction of information from OCR’ed documents presented an unexpected second research area of interest for one of the researchers involved in this project. In the search for OCR’ed documents that we might data-mine for information, Warren recovered other wartime forms such as Red Cross Missing Persons bureau files. These documents contain many disparate pieces of information that are not uniformly present in every one of the documents on hand. For instance, some of the files may name the close friends of the dead soldier, or their perceived nationalities, while others do not mention that information. Some casualty forms may be complete, while others list only the soldier as “missing - assumed killed in action.” At a large scale, this is an interesting problem for researchers because statistical comparison requires a more or less uniform availability of information for everything within the database. The details that reward close reading--the features of documents that are unique to individual documents, such as (for example) handwritten annotations in the margins, scribbles, observations that a doctor or soldier include on one form but not on others he or she fills out--cannot be analyzed using distant reading methods, which look for repetitive features across thousands of documents.
But if distant reading cannot recognize them, they represent a digital opportunity that may be realized in the 3D image, which can be designed using some of the unique details that survive in these individual documents. Drawing on these idiosyncratic details, Warren has experimented with creating a 3D representation of specific wartime events such as the Battle for Regina Trench referred to above. Such representations draw on this non-uniform information as well as the Geographical Information System data that we accumulated in the process of crawling various web pages related to the war. The visualization of the changes over time that this data records, while not straightforward, is an exciting possibility that Warren seeks to realize by experimenting with the use of immersive 3D simulations as a mechanism to represent information.
 Figure 4. An immersive 3D world generated using disparate facts from Great War related databases.
Figure 4. An immersive 3D world generated using disparate facts from Great War related databases.
The screenshot in Figure 4 is a representation of the trenches within the area near the Battle of Vimy Ridge. The representation allows for the merging of data from a number of digital sources: two different maps, a Geodesic server, a botanical database, and the French and German national libraries.
Conclusion
The project has provided us with a number of reflections about the nature of interdisciplinary work. Different fields have different workflows, reward mechanisms and research expectations that are not always compatible with those of colleagues in other disciplines. Historically, the established working model for humanities-computer science collaborations has assigned the humanities scholar ownership of the research question and the computer scientist ownership of the tools used to pursue it. We seek an alternative model of collaboration where both scholars are partners and where the differences of methodologies and opinions are themselves a source of insight. An example has been the interpretation of irony within the era of the Great War.
What we strongly agree on is that while a certain amount of data is available for searches like these, its limited availability in a format that permits the large scale analysis expected of distant reading or data-mining remains an ongoing problem. The availability of affordable computing power coupled with mass storage devices has made the access to massive amounts of information possible, but at this stage only possible.
References
[Dean-Hall 2013] Dean-Hall, Adriel and Robert H. Warren. Sex, Privacy and Ontologies. In Workshop on Search and Exploration of X-Rated Information (SEXI 2013), in proceedings of Sixth ACM International Conference on Web Search and Data Mining (WSDM 2013), 2013.
[Fussell 2000] Fussell, Paul. The Great War and Modern Memory. 1975. Oxford: Oxford UP, 2000. Print.
[Mäkelä et al. 2014] Mäkelä, Eetu, Juha Törnroos, Thea Lindquist and Eero Hyvönen. "World War 1 as Linked Open Data."Semantic Web Journal. IOS Press, 2014. http://www.semantic-web-journal.net/content/world-war-1-linked-open-data-0.
[PCDHN 2012] Partners of the Pan-Canadian Documentary Heritage Network (PCDHN). Linked Open Data (LOD) Visualization “Proof-of-Concept.” 2012. http://rdf.canadiana.ca/PCDHN-LOD/.
[Warren 2014] Warren, Robert H. and David Evans. From the Trenches - API Issues in Linked Geo Data. In Linking Geospatial Data Workshop, London, UK: World Wide Web Consortium (W3C), March 2014.
[Warren 2012] Warren, Robert H. Creating Specialized Ontologies Using Wikipedia: The Muninn Experience. In Proceedings of Wikipedia Academy: Research and Free Knowledge (WPAC2012). Berlin, Germany, 2012.
[Warren 2011] Warren, Robert H. and Shelley Hulan. “Can a Billion Documents Change the First World War?” Stratford Institute of the University of Waterloo Digital Media Series. Stratford, ON, 30 March 2011.
Robert Warren
Contribution
This project statement, Can 20 Million+ documents change the First World War?, offers an engaging introduction to Muninn, an interdisciplinary project which aims to reshape our understanding of the experience and cultural legacy of the First World War through data-mining and digital humanities methodologies.
One hundred years after the outbreak of the conflict, digital humanities and data-mining are in a position to significantly enhance the study of the First World War and to shape the future of this field. In a sense, new scholarly initiatives like Muninn may be seen as a continuation of scholarly enterprises that originated in the 1960s and 1970s with the emergence of a new type of quantitative history supported by advances in computing. Military records – personal services files in particular – were mobilized to illuminate the social composition and anthropological experience of combat between 1914 and 1918 (see Jules Maurin’s work for instance).
Since then, however, the historiography of the war has largely neglected if not wholly abandoned these perspectives. The gradual but undeniable decline of quantitative history and the increasing dominance of cultural history combined, as in other fields of historical research, to consign the analysis of large data-sets to the margins of the historiography. Indeed, one cannot help being struck by the fact that most interpretative debates and controversies pertaining to the First World War continue to mobilize and hinge on a small number of individual testimonies and corpora of limited size.
A project like Muninn has the potential to transform existing approaches to the First World War by enabling the study of data-sets and corpora of unprecedented scale and size. It could also, as the article demonstrates, further our qualitative analysis of primary sources.
The authors specifically set out to mobilize data-mining to approach and reframe conventional issues raised by the literary representations of the war. In effect, they attempted to use war diaries and operational communications to prolong the reflections on the irony of war pioneered by Paul Fussell. Although Fussell’s seminal work remains central to the historical and literary discussion of the conflict, it has been substantially nuanced. As such, one is surprised by the absence of any discussion of Jay Winter’s revision of Fussell’s literary scholarship. While the methodology deployed here can certainly yield important insights into the war experience, I am not entirely convinced irony is the best analytical category to deploy in this context. Even if we were to unconditionally accept that irony lies in the gap between truth and the appearance of truth, between the realities of the battlefield and the commanders’ conceptual understanding of these realities, I am not sure this is the best way to reflect upon the problematic articulation of experience and representation highlighted by the military experience of the Great War.
In principle as well as in actuality, military command is a set of prescriptions based on partial information about a changing operational environment. As a result, the representational gap that the authors chose to emphasize reflects the practical necessities and constraints of warfare; not a literary or representational device.
However, data-mining here allows us to explore what Clausewitz called the “fog of war”; the underlying uncertainties of the conduct of war. Military thought and leadership, from both a didactic and operational standpoints, constitute an attempt bring a semblance of (conceptual and managerial) order to the very complex, fast-changing, and uncertain nature of combat. The orders of battle produced by belligerent armies are but one example to rule over the messiness of war.
In such a context, this article shows how data-mining may allow to render the difficulty to communicate and represent – in literary and conceptual terms – the nature of combat. The article provides insight into the context and nature of communication on the theatre of operations, at a juncture when time and speed are of the essence.
Presentation
The paper offers a valuable discussion of the methodologies required to exploit digitized primary sources and the problematic reliance of scholars on formats like PDF, which hinders the exploitation of massive troves of digital material. The analysis of the CEF medical case files offers a good illustration of the problems raised by the licensing of historical data. It seems to say that most historians – this reviewer included – remain unaware of potential and detrimental impact of licensing regimes on scholarly use and distribution.
To analyse frontline communications, the authors chose to parse the length of messages in a pragmatic and useful move. I would nonetheless encourage them to place their source of choice in the wider organizational (and archival) context. A greater degree of internal critique would in particular underline that war diaries are essentially an instrumental form of recording meant to help officers plan and conduct future engagements.
The proposed analysis further our understanding of the nature of written communications and on the constraints imposed by wartime technologies and conditions.
The paper offers a strong conclusion on the nature of interdisciplinary work, but this could be strengthened by further reflection on the relationship between particular types of sources and specific approaches to historical analysis.
Preservation
I am afraid I cannot speak to or address any of these questions with the expertise the journal and the authors should expect from a reviewer.
Pierre Purseigle
Contribution
The paper, Can 20 Million+ documents change the First World War?, describes in part the collection and integration of data and metadata from numerous sources on the Web relating to WWI. In particular, the authors appear to have attempted to create a linked open data repository relating locations, units, medical reports and battlefield communications. There is little detail on the OCR process, and the contribution itself is unclear, beyond the collection of the materials. There is an individual example research question relating to a particular unit presented, but it’s unclear how linked data or big data were leveraged to achieve the aims: the authors appear to be undertaking relatively simple text analysis (they mention using the style (1) command to analyse the documents for word count an sentence count). The related work section and relationship to the literature is not strong. Some references are made to other collections, but it is not discussed in detail. The modelling process, the choice of entities, the tuning of the OCR process are all lacking. The case is wellmade for using digital tools, and it is interesting to see the reversal of expectations which was found through comparing and contrasting daily traffic of messages, but it’s not clear what the contribution of linked data was in this case, or how the toolchain was helpful vs. the close reading.
Presentation
The goals of the project must be regarded as being extremely ambitious: parsing millions of documents from a globally distributed set of repositories in highly heterogeneous formats, and reconciling them with ontologies, publishing and linking those ontologies and their data, and facilitating analysis. This objective is one which is shared by many other projects with large scale. The project seems to be manifested at the moment with a drupal-based website, and ARC based triple store and some screenshots of a 3-D visualization, and a hosted site publishing the vocabularies and their documentation. These sites are not particularly integrated, from a user experience perspective.
Preservation
There seems to be an awareness of Linked Data best practices, and an effort has been made to publish the data and reuse existing vocabularies and data. A discussion of the fivestar linked data table would be a significant improvement, as would the publication of interlink statements. The vocabularies are welldocumented, but the data itself does not appear to be documented. The system is hosted on a university server, from what I can tell. The platform is opensource, from what I can tell. There is no discussion of sustainability that I can see.