
CEDAR: Linked Open Census Data
Introduction
Census Data Open Linked. From fragment to fabric - Dutch census data in a web of global cultural and historic information1 (CEDAR) is an ongoing (2011-2015) Dutch multidisciplinary national research project. It is funded by the Royal Netherlands Academy of Arts and Sciences2 (KNAW) as part of the Computational Humanities Programme3. Its participants are Data Archiving and Networked Services4 (DANS), the VU University Amsterdam5, the International Institute of Social History6 (IISH) and the Erasmus University Rotterdam7.
The overall goal of the project is to provide easier access to the Dutch historical census data. The intended research audience of the project comprises historians and other humanities scholars interested in historical statistical information. To understand the importance of CEDAR one has to know that for decades efforts have been made by the Central Bureau voor de Statistiek8 (CBS) (Dutch Central Statistical Office), DANS and others to make the Dutch Historic Census better available for the wider public as well as for research. In the Netherlands we have sources from census data going back to 1795. Up to 1971 in each decade a census has been carried out, with different questions and different also in granularity of collected information. The primary remaining sources are books in which tables have been published containing the aggregation of census information. Those books have been scanned. Later, a data entry project has been carried out to transfer the tables into Excel files. Both images and Excel files have been partially indexed and made available via a Content-Management-System for browsing and some search capabilities. However, the digital representation of the Dutch Historic Census in this form is not machine readable, and concerning current Big Data efforts in the Humanities quite outdated. This was the motivation to set up CEDAR, and those Excel files are the heritage from which this project started9.
CEDAR seeks to answer fundamental questions about social history in the Netherlands and the world in automatic, web-scalable and reproducible ways. More concretely, the aim of CEDAR is to publish the Dutch historical censuses (1795-1971) in the Semantic Web, using this dataset as a starting point to build a semantic data-web of socio-historical information. With such a web we will be able to more easily answer questions such as:
- What kind of patterns can we identify and interpret in expressions of regional identity?
- How to relate patterns of changes in skills and labour to technological progress and patterns of geographical migration?
- How to trace changes of local and national policies in the structure of communities and individual lives?
Sometimes, census data alone are not sufficient to answer these questions. CEDAR exploits Web standards10 to make census data interlinkable with other hubs of historical socioeconomic and demographic data. When integrated, these hubs can better support the historical research cycle. The project will result in generic methods and tools to weave historical and socio-economic datasets into an interlinked semantic data-web.
This broad aim touches unavoidably upon many interdisciplinary research areas and audiences. Publishing socio-historical data on the Web in a semantically rich and consistent manner poses fundamental challenges for Knowledge Representation and Reasoning, two of the key fields in Artificial Intelligence (AI). The deployment of tools and methods to achieve these goals in a reproducible and efficient way is closely related with Software Engineering and Computing. On the other hand, Social History, located at the crossroads between history and social sciences, produces fundamental research questions about social change and suggests domain-specific models and standards11 for socio-historical data. The interplay within Computing and the Humanities (the basic components of the Digital Humanities) in CEDAR works two-ways: (a) we use AI and Computing to give infrastructure, scale, formalism and reproducibility to address Social History issues; and (b) we use Social History to inspire AI and Computing with new algorithms, methods and tools.
Related Work
Starting in 1996, major efforts have been undertaken in the digitization of the Dutch historical censuses. In order to provide better access to censuses, the CBS and the Data Archiving and Networked Services (DANS) institute, grown out from NIWI (Het Nederlands Instituut voor Wetenschappelijke Informatiediensten) cooperated in the digitization of the aggregated results from the censuses of 1795-1947. Another goal of this cooperation was to improve the accessibility of the 1960 and 1970 censuses that cover so-called micro data (i.e. registers with precise information about each individual). The first step in the digitization process of the Dutch historical censuses focused more on ‘medium conversion’, resulting in thousands of scans of the books which were published as images. The second major activity was the ‘manual’ conversion (data entry) of these images into Excel files, resulting in over 2300 disconnected and heterogeneous Excel files with different levels of granularity.
CEDAR strongly builds on the outcomes of the Hub for Aggregated Social History (HASH) project (2007-2011, Netherlands Interdisciplinary Demographic Institute, NIDI-KNAW, and Radboud University Nijmegen, RU). HASH aimed to realize a web hub for accessing relevant demographic, social, economic and political data on all Dutch historical municipalities (1812-2000). This was done in four ways: 1) by complementing and correcting datasets that already exist at several institutions, 2) by synchronizing these datasets by means of standardized meta-information, 3) by creating a web portal for immediate access to the data, and 4) by creating an innovative interface for selecting and visualizing the data. Thanks to this workflow, the metadata of the Dutch historical census tables are indexed and can be queried. CEDAR seeks to extend this with fine-grained access not only to metadata, but also to aligned, harmonized and ready-to-process census data, exposed on the Web in a machine-readable and processable way.
First introduced in [Berners-Lee et al. 2001], the Semantic Web was conceived as an evolution of the existing Web (based on the paradigm of the document) into a Semantic Web (based on the paradigm of meaning and structured data). Concretely, the Semantic Web can be defined as the collaboration and the set of standards that pursue the realization of this vision. The World Wide Web Consortium12 (W3C) maintains the Resource Description Framework (RDF), the basic layer on which the Semantic Web is built. RDF is a set of W3C specifications designed as a metadata data model. It is used as a conceptual description method: entities of the world are represented with nodes (e.g. Dante Alighieri or The Divine Comedy), while the relationships between these nodes are represented through edges that connect them (e.g. Dante Alighieri wrote The Divine Comedy). Linked Data13 is the method of publishing and interlinking structured data on the Web using RDF and standard vocabularies14. The Linked Open Data cloud15 is the set of all linked datasets on the Web that use Linked Data.
There have been multiple efforts to use semantic technologies and Linked Data approaches to represent, publish and interlink historical data, including historical censuses, meaningfully on the Web. [Meroño-Peñuela et al. 2014a] offer an up-to-date survey on this subject. More closely related approaches on publishing census data also exist. The 2000 U.S Census16 has an RDF version which provides population statistics on various geographic levels, although the dataset is not historical and it does not harmonize different time-gapped releases. The Canadian health census uses LOD principles to provide greater access to the data and to promote greater interoperability, unachievable with conventional data formats [Bukhari 2013]. Similarly, in the context of a national large scale project regarding the management of socio-demographic data in Greece, [Petrou 2014] has applied LOD techniques to the Greek population census of 2011. A similar goal here is to publish ‘traditional’ datasets into RDF and allow easier access and use of the census by e.g. third parties, aiming to develop a platform within which the Greek census is converted, interlinked and available in a LOD format. The 2001 Spanish Census project is another advocate of applying LOD principles to census data, while encouraging the development of open government initiatives [Fernández et al. 2011]. Using microdata from the 2001 population census, the authors of the Spanish Census project propose a solution for converting the data into open formats allowing greater discoverability, accessibility and integration; a recurrent topic in all of the mentioned projects.
All of the above projects have harmonized RDF census data within the domain of each census year, using micro data as a starting point. Therefore, a hypothetical methodology to harmonize different time-gapped versions of aggregated Linked Census Data, especially by leveraging the externally linked datasets, remains an open, unsolved research problem.
Methodology
The primary format of the Dutch historical censuses (1795-1971) are images of scanned books. A small subset of the 300,000 images17 is available as 507 Excel workbooks, containing 2,288 tables (0.7 % of the data) (see Figure 1). Meaningful historical information is currently hidden in these tables. In order to fully reap the benefits of this dataset, temporal comparisons and cross-connections between these tables are required. However, these tables are highly dispersed, hardly comparable, differently aggregated and non-trivially queryable, mainly due to the temporal gap (about 10 years) between the versions, and the lack of data harmonization.
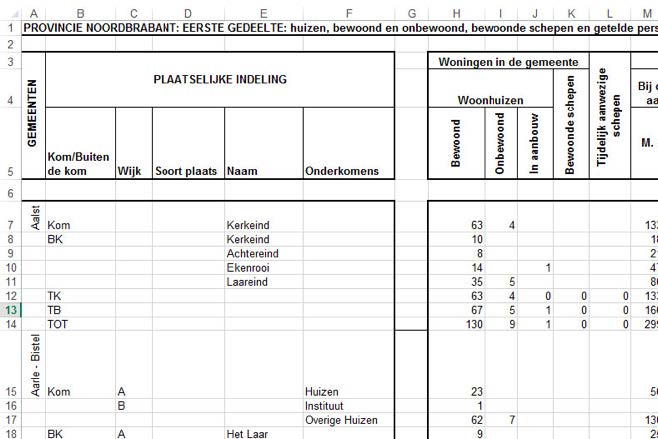
Figure 1. Example of one of the Excel workbooks with a census table.
In order to solve these issues, we use a two-fold approach that combines Linked Open Data (LOD) principles with harmonization practices. On the one hand, we represent the census dataset as LOD using Web standards, making it interlinkable with other hubs of historical socioeconomic and demographic information. On the other hand, we apply state-of-the-art harmonization techniques [Esteve 2003, Ruggles 1995, Meroño-Peñuela et al. 2012, Williamson 2014] to clean, normalize and make the data compatible and comparable.
Linked Census Data
Following standard LOD guidelines18, we exploit the Resource Description Framework19 (RDF), the W3C Web standard for data publishing and exchange on the Web. We transform the 507 Excel workbooks of the dataset into RDF and following the Linked Data paradigm, creating historical Dutch Linked Census Data for the first time. Making extensive use of semantic technologies and LOD principles, we link this dataset to other relevant datasets using standard vocabularies, leveraging specific data classifications, taxonomies and ontologies.
First, we select a standard data model and a set of standard vocabularies that fit the data. Our choice for the former is the RDF Data Cube vocabulary20 (QB), the W3C standard for publishing multi-dimensional data, such as statistics, on the Web in such a way that they can be linked to related datasets and concepts. QB allows us to express the same observations contained in the Excel spreadsheets in RDF, without losing meaning. We extend the model to also preserve the original layout.
Besides QB, the converted dataset in RDF makes use of the following additional vocabularies:
- DCMI Metadata terms: http://purl.org/dc/terms/
- Web Ontology Language (OWL): http://www.w3.org/2002/07/owl#
- RDF Schema: http://www.w3.org/2000/01/rdf-schema#
- Simple Knowledge Organization System (SKOS) RDF Schema: http://www.w3.org/2004/02/skos/core#
- XML Schema Definition (XSD): http://www.w3.org/2001/XMLSchema#
Once transformed into RDF, we refer to the resulting dataset as CEDAR’s raw data layer. The RDF graph representation of one cell is shown in Figure 2.
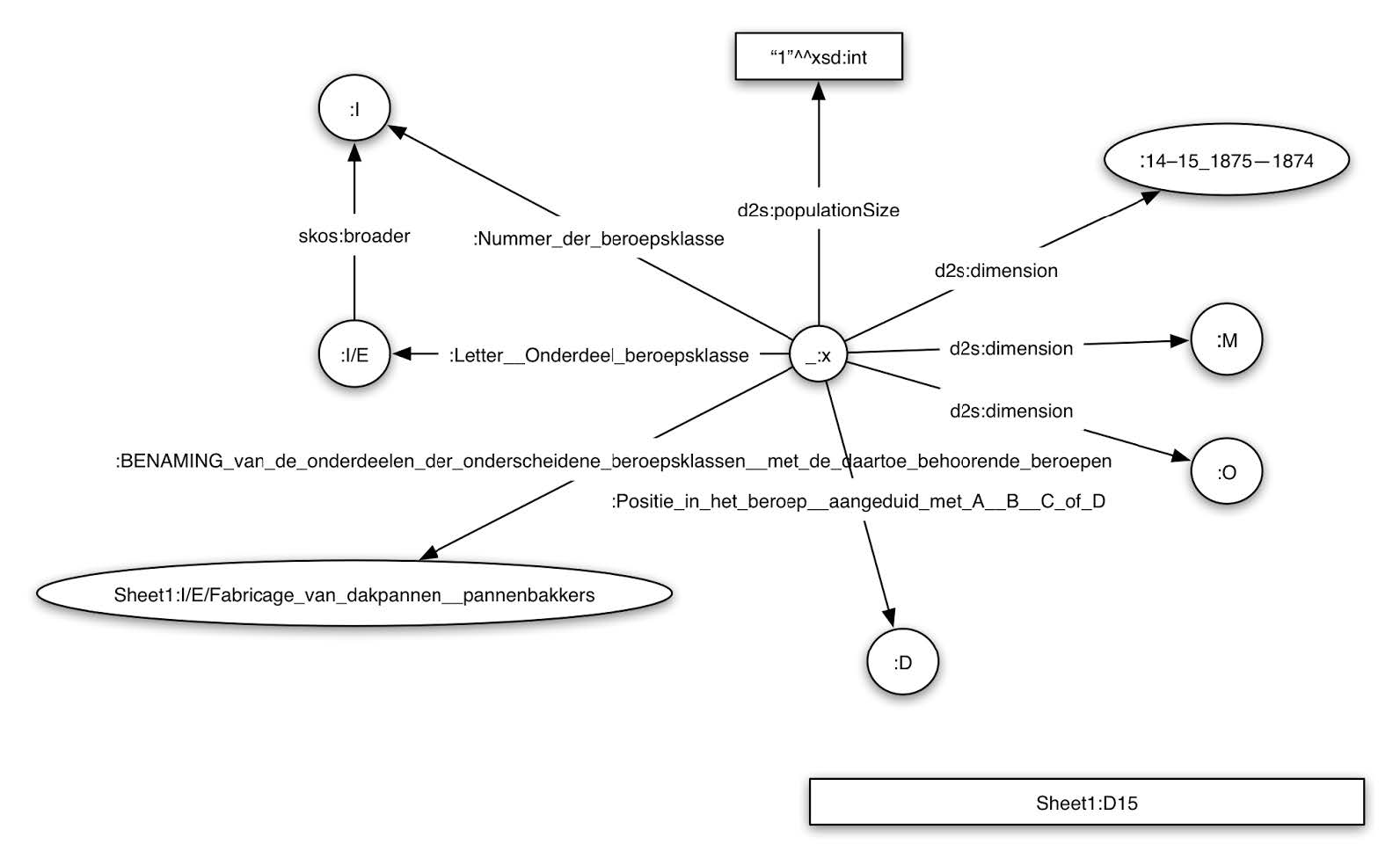 Figure 2. RDF graph representation of one of the cells in the census tables.
Figure 2. RDF graph representation of one of the cells in the census tables.
Census Harmonization
Although RDF allows us to represent the data in the tables in a fine granular way, the problem of harmonizing the data remains unsolved. In order to implement this harmonization, we apply a two tier model (see Figure 3): an upper tier, allowing access to harmonized census data; and a lower tier, allowing access to the original historical primary sources. We implement these two tiers in three modules: the raw data (containing a direct translation of the numbers and concepts in the tables, as described before), the annotations (with corrections and comments from the dataset creators and curators), and the harmonization (linking and standardizing heterogeneous census entities).
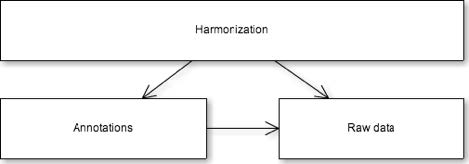
Figure 3. Harmonization, annotation and raw data layers.
When dealing with historical census data researchers need to make sense of all the irregularities in structures, classifications and deal with redundant, inconsistent or erroneous data. Currently harmonization is still very much a loose term for researchers, encompassing different views and methods on how data should be restructured. When working with historical censuses, due to their nature, researchers are often forced to create their own classifications or use existing systems for comparative research. In historical research harmonization is often defined as the creation of a unified, consistent data series from disparate census samples when dealing with historical census data [6]. As harmonization is not a standard process we want to leave room for experimentation and different interpretations of the data. Harmonization therefore strongly relies on interpretation and specific goals. Moreover, access to source data must always be guaranteed. We separate the raw data, annotations and harmonization layers to accommodate this (see Figure 2). Harmonization of aggregated statistical data consists of a set of practices such as rules, data transformations, cleaning, standardization, use of standard classification systems, data smoothing, interpolating, extrapolating etc. We apply all these techniques in the harmonization layer, building on top of data in the raw layer and always considering the expert annotations in the annotations layer (see Figure 2).
Contribution
One of the earlier tasks of CEDAR was to convert the original census tables contained in Excel tables into RDF. Unfortunately, none of the tabular-to-RDF conversion tools available21 was suitable for CEDAR: heterogeneity of the layout, column and row headers spanning various cells, and the lack of semantic expressivity made clear that a special-purpose tool was needed. To solve this, we coded, together with Data2Semantics22 (COMMIT, VU University Amsterdam), TabLinker23, a supervised Excel-to-RDF-QB converter. TabLinker reads markup of Excel files to produce faithful RDF QB representations, works virtually with any Excel file in a generic way, and can be customized by several parameters.
Using TabLinker and an expert-based markup of the source files, we transformed the Dutch historical census tables into RDF. Loaded into a triplestore, the entire graph database is available for users and machines alike to query live on the Web via a SPARQL (a SQL-like standard language to query Linked Open Data) endpoint24. There is work in progress on generating SPARQL documentation to enable historians, social scientists and humanities scholars (in addition to computer scientists) to write their queries. Complete dumps of the converted data are also available for download25.
However, the conversion alone does not produce a harmonized dataset: many values differently spelled need to be mapped together, variables need to be aggregated at different geographical levels, etc. To address harmonization, we take several approaches:
- We first harmonize automatically as many variables as we can, with a set of harmonization scripts that produce human-readable documentation26
- We then ingest these automatic harmonization into CEDAR Harmonize27, a web interface that allows knowledge experts to fine-tune the harmonization process
- In order to standardize common statistical historical variables, like demographic structures, housing types, occupational classes and statuses, or religious denominations, we build bottom-up classification systems from the raw data. To achieve this, we have developed TabCluster28 [10], an algorithm that builds taxonomies out of flat lists of values by combining lexical attributes (using hierarchical clustering) and enriches them semantically (using knowledge in DBpedia and Wordnet).
In order to produce a 5-star dataset29 we produce links that connect the CEDAR dataset to other LOD datasets. Concretely, we issue links (see Figure 4)30:
- To the Historical International Standard Classification of Occupations31 (HISCO)
- To the Amsterdamse Code and URIs of gemeentegeschiedenis.nl (which point to resources in DBpedia and GeoNames)
- To occupations in the ICONCLASS32 system
- To/from the Dutch Ships and Sailors33 dataset
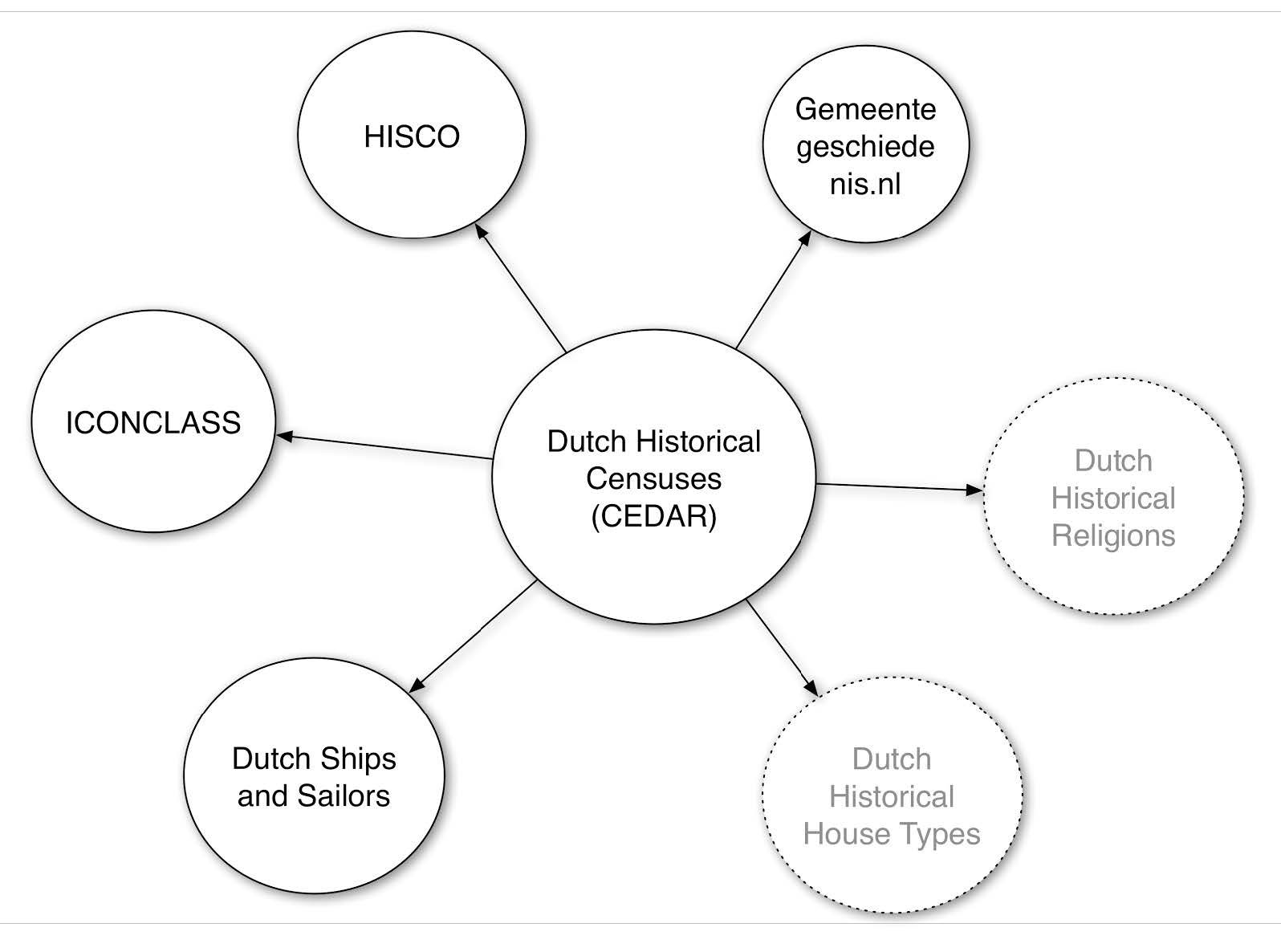 Figure 4. Linked datasets to/from CEDAR.
Figure 4. Linked datasets to/from CEDAR.
CEDAR aims at highly reproducible research. Ideally, we target a platform that can run the complete transformation and harmonization pipeline, integrating all the necessary steps to produce a top quality LOD dataset. To achieve this, we are developing the CEDAR Integrator34, a platform integration workflow that will automatise the semantic publication pipeline, from isolated Excel files to RDF ready-to-publish Linked Census Data.
A fundamental aspect of CEDAR is to contribute to using Artificial Intelligence and Computing to support the historical research cycle. To this end, we have conducted a survey on the state-of-the-art of applying semantic technologies to historiography [Meroño-Peñuela et al. 2014b]. But beyond this, we are concerned about delivering tools and systems to social historians that support historical research. We do this through the following list of concrete contributions.
Comparability: Layout and semantics
The main pitfall of the original form of the dataset, Excel spreadsheets, is that variance and irregularities in (a) the layout, and (b) the definitions of statistical variables in these tables hampers an easy access to the historical data they contain. As a result, historians need to manually open these files one by one (the dataset contains more than 2,000 of them) and manipulate data items in a non-reproducible way, in order to get data that provides answers to their research questions. With the data model provided by RDF Data Cube (see Methodology section) we overcome irregularities in the interpretation of these changing layouts. With the harmonisation and integration workflows (see Linked Census Data and Census Harmonization sections), we overcome irregularities in varying definitions of statistical variables. Combining the two, we generate, for the first time, a database which is longitudinally accessible and comparable by historians: meaning that they don't have to deal with disparate files, and are able to get answers to their questions using the SPARQL query language.
Standardisation of historical statistical variables
The representation of the Dutch historical censuses as Linked Data makes it very easy to link data points of the dataset to other datasets. This way, for instance, we can say that the value 'vrouwen' (women) of the population count in Amsterdam in 1889 is the same value 'SDMX:Female' of the variable 'SDMX:Sex' of the international standards used to define statistical variables about sex (SDMX35). We use this easy linking to standardise values in historical data in general, like historical occupations, historical religions, historical house types, etc. Without such easy linking, historians would need to create classification systems and variables for every specific case. With proper standardisation, we also make it easier for data consumers to better understand and use the dataset.
Enrichment from/to other datasets
Similarly, the representation of the Dutch historical censuses as Linked Data allows us to link resources of the dataset with resources of other Web datasets easily. For instance, users can confront the population counts of Dutch important cities in the 18th, 19th and 20th centuries (from our dataset) with the current population counts available on the Web (from e.g. DBpedia, the Linked Data version of Wikipedia) using a single SPARQL query against both data sources. This way, users of the census data can enrich their queries with other Linked Data they find on the Web that they consider useful or interesting to merge. Likewise, other data sources can be enriched exactly the same way, by querying the census data from our SPARQL endpoint and adding it to the results.
Automation of longitudinal analysis
Combining the three previous points, historians have now a uniform and automated access to the information contained in the original tables36. Moreover, the publishing of these data as Linked Data on the Web makes it possible to anybody to reference any single data point through its URI (and to dereference it to retrieve useful information), contrary to what happens in closed systems, where data (even if integrated, harmonised and standardised) is left in an isolated and non-accessible or referenceable way.
Study of change over time
Last, but not least, such a uniform access opens up the study of social change in the Netherlands in the period 1795-1971. Moreover, we study the fundamental question of how historical concepts have drifted in meaning over time, through the use of statistics and Machine Learning over different archived dataset/ontology versions37 [Meroño-Peñuela et al. 2013]. Such study was very deeply hampered before, due all issues discussed before. Now, automatic conversion, linkage and standardisation are allowing us to develop visualizations and statistical analyses38 that allow historians to better understand phenomena beyond the unmanageable original format of the data, at the same time they help on detecting and solving errors in the proposed methodology.
We also enable the exploration and validation of our results by ongoing development of analysis tools and visualizations39. This way, we provide methods to leverage Linked Census Data by humanities scholars, including historians, social historians and social scientists, allowing fine-grained querying via SPARQL (experimentally, also via natural language interfaces like hald40), and linked data discovery and exploitation via visualization and Linked Data browsing41. In general, we support the historical research cycle by adding as much automation, intelligence and semantics as we can. Prototypes for web interfaces gathering an integrated access to all browsing features are being developed in parallel projects42.
We plan preservation and sustainability of CEDAR data and services at different levels. First, we make available all data and source code via a GitHub profile43, open for any users and developers who wish to collaborate. Second, we strongly collaborate with DANS to archive research results (data and tools) in EASY44, the Trusted Digital archive of DANS45. We are especially interested in all issues that preservation of Linked Data arises46.
Most of the described contributions are work in progress. Technical documentation and reports are constantly updated and available online47.
Peer Review
CEDAR is part of the Computational Humanities Programme of the KNAW, and is part of the eHumanities group48. There was a closed call for projects within the humanities institutes of the KNAW. All proposals were sent for international peer review, and final decisions were made by the Computational Humanities Programme Committee, consisting of senior scholars in digital humanities based in Dutch universities. CEDAR is composed of two PhD positions and one postdoc position. The recruitment of staff for those positions took place in an open competition.
CEDAR meets regularly once a week, and organizes an annual international symposium49 where all developments and publications are shared and discussed. We invite international guests from related research fields and senior scholars from the KNAW and beyond, and welcome any interested participants - we are keen on being open. CEDAR also participates in the annual eHumanities group symposium and other events organized by the group.
Policy
Principles of data management and curation are core to CEDAR. Once finished, CEDAR will deposit all the data in EASY, a Trusted Digital Repository, which will be given proper persistent identifiers. We will motivate users to properly cite the data, by leveraging these identifiers and the applied semantic representations. Thanks to our LOD approach, the provenance of any census data item, down to its data source, can be traced back following semantically rich web links - something that can only be achieved following LOD methodologies.
CEDAR has been chosen as a use case for a current European project: PRELIDA – Preserving Linked Data50. This project aims to prepare guidelines to archive and preserve Linked Data. It addresses questions about where to draw a boundary when preserving part of the Linked Open Data cloud, and how to not only archive the data and data models, but also the software which allows to deploy them [Batsakis, S. et al. 2014].
Original census materials, as well as the original CEDAR dataset, are open data and owned by the Central Bureau voor de Statistiek51 (CBS). All tools developed in CEDAR are open source (specifics on licensing pendant).
- 1. See http://www.cedar-project.nl/
- 2. See http://knaw.nl/
- 3. See http://ehumanities.nl/
- 4. See http://dans.knaw.nl/
- 5. See http://vu.nl/
- 6. See http://socialhistory.org/
- 7. See http://www.eur.nl/
- 8. See http://www.cbs.nl
- 9. See legacy data at http://www.volkstellingen.nl and https://github.com/CEDAR-project/DataDump/tree/master/xls
- 10. See http://www.w3.org/standards/
- 11. See http://www.clio-infra.eu
- 12. See http://www.w3.org/
- 13. See also http://www.w3.org/DesignIssues/LinkedData.html
- 14. A summary of these vocabularies can be found at http://lov.okfn.org/dataset/lov/
- 15. A summary of contained datasets can be found at http://linkeddata.org/
- 16. See http://datahub.io/dataset/2000-us-census-rdf
- 17. The biggest subset of it is currently available at https://easy.dans.knaw.nl/ui/datasets/id/easy-dataset:44159
- 18. See http://linkeddatabook.com/editions/1.0/
- 19. See http://www.w3.org/standards/techs/rdf
- 20. See http://www.w3.org/TR/vocab-data-cube/
- 21. See http://www.w3.org/wiki/ConverterToRdf#Excel
- 22. See http://www.data2semantics.org/
- 23. https://github.com/Data2Semantics/TabLinker/
- 24. The SPARQL endpoint is available at http://lod.cedar-project.nl/cedar/sparql and http://lod.cedar-project.nl/cedar-mini/sparql
- 25. Downloads available at https://github.com/CEDAR-project/DataDump
- 26. See https://github.com/CEDAR-project/Integrator
- 27. See https://github.com/CEDAR-project/Harmonize
- 28. See https://github.com/CEDAR-project/TabCluster
- 29. See details at http://www.w3.org/DesignIssues/LinkedData.html
- 30. All linksets are available online at https://github.com/CEDAR-project/DataDump/tree/master/links
- 31. See http://historyofwork.iisg.nl/
- 32. See http://iconclass.org/
- 33. See http://ghhpw.com/ships_and_sailors.php
- 34. See https://github.com/CEDAR-project/Integrator
- 35. Statistical Data and Metadata Exchange; see http://sdmx.org/
- 36. See e.g. http://lod.cedar-project.nl/cedar/data.html
- 37. Experiment results and source code available at https://github.com/albertmeronyo/ConceptDrift
- 38. See e.g. http://lod.cedar-project.nl/cedar/stats.html
- 39. See http://goo.gl/I3xyYz, http://goo.gl/JHEjXL and http://www.cedar-project.nl/visualizing-sparql-query-results-on-the-census/
- 40. See repository at https://github.com/CEDAR-project/hald
- 41. See http://lod.cedar-project.nl:8888/cedar/ for an interface that allows browsing all published census Linked Data
- 42. See http://nlgis.nl/
- 43. See https://github.com/CEDAR-project
- 44. See https://easy.dans.knaw.nl/
- 45. See https://assessment.datasealofapproval.org/assessment_101/seal/html/
- 46. See http://www.prelida.eu/
- 47. See https://docs.google.com/document/d/1Y7oPwM155Xz2YBNRb1m2-gAXIQfY47_5Ai0GwhwcVtk/pub and https://docs.google.com/document/d/1iMr65cC4tuSfKvqC6Y3c9tzNtOphXQ7DBj9I3o1811o/pub
- 48. See http://www.ehumanities.nl
- 49. See http://www.cedar-project.nl/cedar-minisymposium-march-1st-2013/ and http://www.cedar-project.nl/cedar-minisymposium-march-1st-2013/
- 50. See http://www.prelida.eu
- 51. See http://www.cbs.nl/
References
- [Batsakis, S. et al. 2014] Batsakis, S. et al. (2014) PRELIDA Deliverable 3.1. - State of the art assessment on Linked Data and Digital Preservation. (With further comments and text contributions from Albert Meroño-Peñuela, Peter Doorn, Marat Charlaganov and Menzo Windhower). Project report. Web resource http://www.prelida.eu/sites/default/files/D3.1%20State%20of%20the%20art.pdf (2014)
- [Berners-Lee et al. 2001] Berners-Lee, T. et al. The Semantic Web. Scientific American, 284(5) (2001): 34-43.
- [Bukhari 2013] Bukhari, A. and Baker, C. J. O.. The Canadian health census as linked open data: towards policy making in public health. In Data Integration in the Life Sciences (2013).
- [Esteve 2003] Esteve, A. and Sobek, M.. Challenges and Methods of International Census Harmonization. Historical Methods, 36(2), 37-41 (2003).
- [Fernández et al. 2011] Fernández, J. et al. Publishing open statistical data: the Spanish census. In Proceedings of the 12th Annual International Digital Government Research Conference: Digital Government Innovation in Challenging Times (dg.o '11). ACM, New York, NY, USA, 20-25 (2011).
- [Meroño-Peñuela et al. 2012] Meroño-Peñuela, A. et al. Linked Humanities Data: The Next Frontier? A Use-Case in Historical Census Data. proceedings of the 2nd International Workshop on Linked Science 2012 (LISC2012), ISWC 2012, Boston, USA (2012)
- [Meroño-Peñuela et al. 2013] Meroño-Peñuela, A. et al. Detecting and Reporting Extensional Concept Drift in Statistical Linked Data. Proceedings of the 1st International Workshop on Semantic Statistics (SemStats 2013), ISWC 2013, Sydney, Australia (2013).
- [Meroño-Peñuela et al. 2014a] Meroño-Peñuela, A. et al. Semantic Technologies for Historical Research: A Survey. Semantic Web Journal (in press) (2014)
- [Meroño-Peñuela et al. 2014b] Meroño-Peñuela, A. et al. From Flat Lists to Taxonomies: Bottom-up Concept Scheme Generation in Linked Statistical Data. Proceedings of the 2nd International Workshop on Semantic Statistics (SemStats 2014), ISWC 2014, Riva del Garda, Italy (2014).
- [Petrou 2014] Petrou, I. and Papastefanatos, G. Publishing Greek Census Data as Linked Open Data. ERCIM News 2014(96) (2014)
- [Ruggles 1995] Ruggles, S. The Minnesota Historical Census Projects. Historical Methods, 28(1), 6-10 (1995).
- [Williamson 2014] Williamson, L. E. Methods for Coding c19th and c20th Cause of Death Descriptions from Historical Registers to Standard Classifications. European Social Science History Conference 2014, Vienna (2014). https://esshc.socialhistory.org/esshc-user/program/?day=15&time=32&paper=2709&network=36
Ashkan Ashkpour
Andrea Scharnhorst
Christophe Gueret
Sally Wyatt
Contribution
Some time around 1086, William the Conqueror commissioned a survey of his lands to discover what it was he had conquered. The Domesday Book is a great survey, measuring the numbers of people in various social roles, the holdings and their value [domesday]. The immediate value of good census data was apparent long before the XIth; Century, and today such data is the baseline for a vast array of data analysis for diagnosis and prediction of social and economic trends.
The Domesday book was recorded by hundreds of hands, gathering data from church records, testimony of lords and other lists. The questions asked were of their time, with a focus on agrarian output, and ownership before and after the Norman Conquest. Censuses are not neutral documents: they are compiled with a purpose, and with an intended audience. In earlier times it might have been a King surveying his new conquest, or for more mundane economic planning. Occasionally, the answers to the questions can be a place where individuals can stand up to be counted, or not, beyond the normal measure [Liddington 2011]. A key requirement for any numerical question to be answered is to be able to compare. Without context, it is impossible to say whether it is good or bad that there were two shoemakers recorded in Utrecht in 1899 [shoesparql].
The contribution of the CEDAR Project is to provide access to the Dutch Census dating from 1795 until 1971, but evidence from the above examples, and countless others, points to the value of census documents, especially when properly contextualised and linked. The key audience for their work is a 'research audience', specifically historians. The project statement outlines key social-historical questions, inquiries into the nature of geographical, economic and cultural evolution, as well as distribution over time. From the start, the project recognises that there are two integrity challenges to address: the 'internal' consistency of the census data, and the 'external' consistency or interlinks with additional data types.
The history of the project, as reported in the project description, will be a familiar challenge to many: previous investment has resulted in the creation of a large collection of excel-based 'tabular' representations of the written census forms. A recurring challenge with this kind of literal process of digitisation is that it creates human-readable but not machine-readable data. Even to answer questions from within the census collection is laborious: it requires manually opening dozens of individual files and reconciling the data categories and values by hand. This is likely to be error-prone and difficult. The authors have identified several compelling motivations for the transition to a more modern, machine-readable, open format: that which the LOD approach promises. The need to be able to cross-reference, to be able to create an enduring record, and the need for internal consistency adequate for machine-assisted historic inquiry are well described.
There are two main areas where there could be room for future improvement in the way the project is presented: the first would be to facilitate the exploration of the data set through browsing or visualisation; the second would be to provide more guidance and introduction to the dataset and, especially, the project’s tools. The presentations and papers on the page are useful, but a more guided indication of the decisions around data modelling would help. The DHCommons project statement could provide a good basis for this. It would be greatly strengthened by a much more explicit description of why different attributes and shared vocabularies were chosen. Another aspect is that, for non-Dutch speakers, the schema and instance values may not be very accessible; incorporating best practices for multilingual Linked Data publishing would improve accessibility.
Similarly, suggestions for future work on the data/back-end side include the incorporation of better interlinks with the general background LOD cloud, as well as a clear statement of the data quality, categories and schema design. The separation of harmonisation, raw data, and interpretation is a very good example of how to approach the challenge of reversible transformation: future investigators will more easily be able to uncover what changes, right or wrong, were applied, which is of huge value.
Finally, the project website could be updated to describe the rich collection of software in the github, and guidance on its relationship to standard tools such as openrefine, and other LOD and triplification tools.
This work explicitly supports both D and H in Digital Humanities, and demonstrates an impressive contribution by showing best practice for handling highly inconsistent data inherited from legacy digitisation. The creation of systematic pipelines for processing, which facilitate experts in creating consistent, machine-readable data from digital artefacts is an important contribution. Data cleaning is a major concern in the commercial and research domains, especially given the pressure to move towards 'Open' and 'verifiable' practices in government, research and society in general. The assumption that just because something is shaped like a table that it can be processed that way is a dangerous one. The 'D' is therefore supported in the open-source toolset. The 'H' contribution is undoubtedly in the collection itself, which is of significant value to European and perhaps global historical, social and economic researchers. There is also a 'DH' contribution in the practice and selection of categories and attributes, though this work perhaps needs to be developed further. Breaking such valuable data from a binary storage format, and an inconsistent one at that, is of significant value.
One question which will be interesting to see if the project can answer is whether it is in fact feasible or practical to train humanists in the use of SPARQL? To what degree will this represent a barrier to some experts wishing to explore or use the data?
Presentation
The presentation of the project itself is consistent with a web page from the preliminary stages of the project, updated with publications and posts. It could be more informative about the current state of the project, and the approach of offering open access to both the software (listing the components therein) and the data (both the schema and the instance information).
Currently, the web page integrates the project activities and sparql endpoint well, but does not integrate the content on github such as the sourcecode and data dumps. The github site is slightly sparse, and there is significant heterogeneity between the layout, documentation level, usage information and templating for each of the repositories and their components. However, the content and code are obviously of high value and quality, and so it is a matter of documentation, guidance and layout, and perhaps updating the user interface.
The websites themselves are clear and reasonably consistent with the use of bootstrap. They require modern browsers, but this is best practice with LOD applications.
Preservation
Here are four aspects to the project from a Preservation perspective:
The Census Data
1. The data itself is stored on Github, along with the mapping rules. The provenance information is both query-able, and visible as transformation files. The separated raw and harmonized content is visible, all of which provides an easily reversible and verifiable view of the data.
Software for processing, and publishing
1. The tools for the data pipeline are published on the Github platform, which is a commercial service. However, it is one that seems as likely as any to endure, and it allows easy downloading of the version-controlled software and its changesets, in an open and accessible format
2. The software for hosting the service is a javascript-based front-end (http://yasqe.yasgui.org/) with the triple store apparently being Virtuoso. The latter is a well-known standard tool in LOD publishing, while the former appears well maintained by the Data2Semantics group
3. Some of the software is implemented in Python, leveraging the common libraries for Linked Data. Naturally, there is limited documentation at this point, but as the project matures it would be useful to separate data, source code and sample data for easier portability to other applications
Licenses
1. Much of the software is open-source, under the MIT, LGPL or GPL licenses. Some repositories incorporate LICENSE files, some do not, and there is inconsistent use of license headers and copyright statements. Again, this is not particularly an issue until long-term archiving or more general release is envisaged.
2. The data itself has no obvious copyright statements. The web content is marked Copyright of the Project. The Web endpoint contains a copyright statement for DANS. I was unsure as to the license status of the data, the queries and the LOD data itself.
LOD Practice
1. Will there be an on-going process of interlink discovery and RDF equivalence statements? Initial work seems to demonstrate that the schema builds upon parts of the established LOD vocabulary, which is in line with best practice. However, the use of a mix of natural languages in the different elements of the schema might be a barrier to non-speakers of either language.
2. The example queries seem to indicate that some of the data urls include port numbers (e.g. "http://lod.cedar-project.nl:8888/cedar/resource/BRT_1947_B6_T-S0-Y221-h” ). This might not be ideal, moreover there is a question about whether these are 'cool' uris, and whether a project website is a suitable persistent location. Similarly, some data includes 'bit.ly' shortened links, which do not appear to redirect properly.
3. Institutional support through both the DANS trusted preservation platform and the PRELIDA project point to a highly positive preservation policy, particularly if the artefactual irregularities in some of the data can be overcome.
Overall, for a project in progress, the maintenance, preservation and provenance aspects of the software, service, and data reflect a clear understanding of the long-term issues.
References
[cooluris] 'Cool URIs for the Semantic Web' http://www.w3.org/TR/cooluris/
[domesday] UK National Archives, Survey and making of Domesday, http://www.nationalarchives.gov.uk/domesday/discover-domesday/making-of-domesday.htm
[Liddington 2011] Jill Liddington, Elizabeth Crawford, 'Women do not count, neither shall they be counted': Suffrage, Citizenship and the Battle for the 1911 Census. History Workshop Journal 71:1 (2011): 98-127.
[shoesparql] Cedar Example Query from http://lod.cedar-project.nl/cedar/data.html.
Alexander O'Connor
Contribution
The CEDAR project collects Dutch census records from 1795 to 1971, and successfully accomplishes the arduous task of moving from scans of the records to a fully-queryable dataset representing the information in those scans. The data thus made available will be extremely helpful to historians, sociologists, and many other humanists. Several features of the data make it extremely useful across many disciplines. For example, the longitudinal nature of the data allows for systematic and methodical analysis of changes in population, occupations, housing, and other factors over a long stretch of time. Moreover, CEDAR took great care to maintain the original structure and labels from the census records, even while harmonizing them to allow consistent queries against the data. The result is that it is possible to trace not only the data recorded by censuses, but also the changes to the questions asked. As database designers know, the structure of a database reflects and embeds its own set of values and interests. Just so, the structure of the census itself and how it changed over time will reveal evolving concerns and priorities of the government.
The technical contributions of the project are perhaps more important. Prior efforts to create a pipeline from scanned tabular data, which might or might not be consistent, into a queryable database has been fraught, at best. CEDAR has developed several open source tools, many of which build upon and refine existing technologies, to make this transformation possible, using established standards. Choosing the Resource Description Framework (RDF) as the target data format will steepen the learning curve for many digital humanists seeking to use the data for their own research. Indeed, the complexity of some of the vocabularies and ontologies used and the relations built into the data will likely require some learning time even for experienced users of RDF, its query language SPARQL, and Linked Open Data. However, that steep journey will be rewarded by the richness of the data available due to that choice, for example from CEDAR's ability to leverage existing RDF datasources.
The creation of a 'scan-to-SPARQL' workflow for tabular data can be a model for other projects using census or similarly structured data, or at least an example that it is possible. Replication and modification of the process, both technologically and organizationally, will likely call for significant and sustained effort. CEDAR is working on the technology side of this, but organizational replication remains an open question. For example, the important step of human intervention from subject experts to harmonize disparate concepts in the raw data into a coherent structure will be a complicated process, as CEDAR acknowledges.
Presentation
The project's web site, writ large, offers many resources for understanding and interpreting the data, its creation, and uses. It is well designed, frequently updated, and presents a strong sense of a very lively project. The real significance, though, is the SPARQL endpoint itself (http://lod.cedar-project.nl/cedar/data.html), from which anyone can query the data -- the main product of the project.
As with any RDF data made available for SPARQL, offering example queries is an essential guide for newcomers to the data. CEDAR makes a good decision in its example queries by separating them into three categories: Basic Queries, Mini Project Queries, and Error Detection Queries.
The basic queries offer helpful examples that demonstrate the kinds of data available and basic patterns for exploring different kinds of data. They also show the interesting possibilities of the data. For example, one example query is "Number of shoemakers for each census year for each province", demonstrating the possibility of the dataset for exploring changes in occupations temporally and geographically. As mentioned above, the complexity of the data structures used requires a fair amount of time exploring how to create variations on the example queries. In this example, trying a different occupation called for a bit of digging into the particular occupation level of data.
The mini project queries look to recreate information about the surveys themselves, for example "Reconstructing Hierarchical Headers". This separate categorization of query gives some hints at a different type of research question that the data could respond to.
Last, the error detection queries provide a nice nod to a fact that anyone who works with datasets of any size must acknowledge: all datasets have messy or wrong values. Any researcher will need to identify ways in which their conclusion could be influenced by quirks in their dataset, and this set of example queries is a thoughtful reminder of that.
The example queries, of course, are aimed at the technologist familiar with SPARQL, but they also nicely invite a conversation between a technologist and a less technical humanist about possibilities for research directions made possible. Again, much learning would be required of both to get a solid grasp on the nuanced details of what is available, and how to query it.
Preservation
CEDAR has established policy for preservation of its data, and is conscious of the need to preserve the software it has developed to create the data. All data and code are available on GitHub, and it has been quite rightly chosen as a use case for PRELIDA (Preserving Linked Data), which is exploring and developing practices that address these issues.
Patrick Murray-John
About
Title
Web Developer, Omeka dev team manager
Affiliation
Tool expertise
Collaboration
Collaboration availability
Maybe available, please ask
Collaboration type